Welcome to our improved and redesigned version of Kriptopolis.com! If you are enthusiastic about casinos and cryptocurrencies, this is your new go-to site. Here is where you will find valuable and informative recommendations, tips, and advice from our crypto casino experts. Our up-to-date reviews and articles will guide you through the vast sea of information about cryptocurrency gambling sites. Learning new things doesn’t have to be boring, and we’re here to prove that.
What Is Kriptopolis.com?
With Kriptopolis.com, we aim to provide our readers with suggestions, tips, and recommendations about the best online crypto gambling sites in 2026. We are fully aware that finding a legitimate cryptocurrency casino can be quite challenging nowadays. That’s why we made sure that all of our recommended operators are safe, secure, and licensed by reputable gambling authorities. Additionally, all of the casinos you’ll see on our pages have rich game selections and fantastic bonuses and promotions.
What’s Changed in Kriptopolis.com?
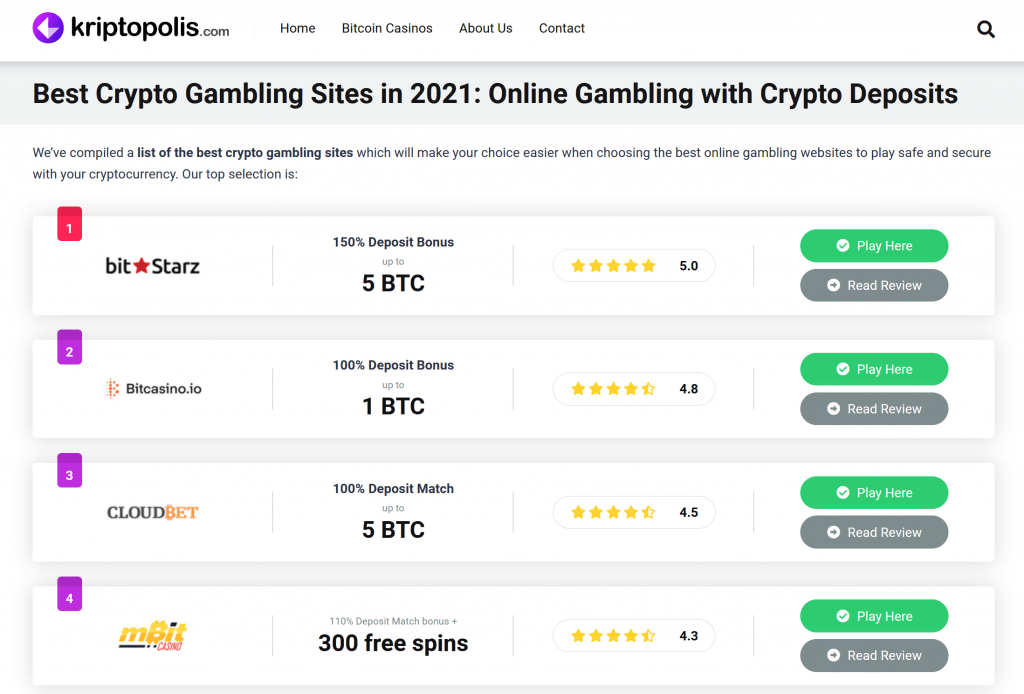 We have worked tirelessly to improve the design, add new elements, rework our formats, and optimise the website so the information is easier to digest. Additionally, we ensured that our guides are easy to read by implementing quick-navigation tables and improving our font pattern. Our research strategies have also been improved – we’re putting more time than ever into testing and verifying the cryptocurrency casinos you’ll find on our lists.
We have worked tirelessly to improve the design, add new elements, rework our formats, and optimise the website so the information is easier to digest. Additionally, we ensured that our guides are easy to read by implementing quick-navigation tables and improving our font pattern. Our research strategies have also been improved – we’re putting more time than ever into testing and verifying the cryptocurrency casinos you’ll find on our lists.
What Are the Benefits of Using Kriptopolis.com?
Becoming a regular reader of Kriptopolis.com comes with many perks. Not only will you always be the first to find about the changes in the cryptocurrency casino industry, but you will also receive guidance, tips, and recommendations from our seasoned experts. There is indeed a lot to learn about cryptocurrency casino sites, but we’re here to make it easy.
As you might know, we take safety and security very seriously. That’s why we ensure that all of our listed operators and casino sites are entirely legitimate and trusted. We are constantly monitoring the country’s law and legislation changes, and we make sure that our guides and reviews are up-to-date. Kriptopolis.com is strictly against illegal gambling, and we will never present you with operators that are untrustworthy or have no licence.
What to Expect From Kriptopolis.com?
With Kriptopolis.com, we will continue our mission of providing our readers with safe and secure platforms. We will keep on researching and monitoring everything that goes on in the crypto casino industry. Kriptopolis.com has a little surprise for BTC enthusiasts who look forward to playing at the best Bitcoin casinos in 2026. We have prepared quite a few more valuable and informative guides. With our tips and recommendations, you can definitely navigate the crypto casino sites smoothly and safely.